

محیط تولید در گوگل از دیدگاه sre
دیتاسنترهای گوگل بسیار متفاوت تر از بسیاری از دیتاسنترهای مرسوم و مزارع کوچک سرور هستند. این تفاوت ها هستند که مشکلات و موقعیت های اضافی را به ارمغان می آورند.
این فصل درباره چالش ها ، موقعیت ها و تکنولوژی های به کار گرفته شده در دیتاسنترهای گوگل صحبت می کند.
سخت افزار
بیشتر منابع محاسباتی گوگل، در دیتاسنترهای طراحی شده توسط گوگل همراه با توزیع نیروی اختصاصی، سیستم سرمایشی، سیستم شبکه ای و سخت افزار محاسباتی می باشد. برخلاف دیتا سنترهای استاندارد، سخت افزار محاسباتی در تمام دیتاسنترهای گوگل یکسان است.در ادامه ما از واژگان زیر به جای سخت افزار سرور و نرم افزار سرور استفاده می کنیم:
ماشین : تکه ای از سخت افزار
سرور : نرم افزاری که سرویس ارائه می دهد
ماشین ها می توانند هر نوع سروری را اجرا کنند، پس ما ماشینی را به سرور خاصی اختصاص نمی دهیم.
ما فهمیدیم که این استفاده از کلمه ی سرور، غیرطبیعی می باشد. استفاده عامیانه از کلمه سرور، با معنی کلمه ماشین، در “یک باینری که network connection قبول می کند” به تداخل می خورد، اما تفاوت بین این دو زمانی مشخص می شود که ما درباره محاسبات گوگل صحبت می کنیم.
هنگامی که با استفاده ی ما از کلمه ی سرور آشنا می شوید، برای شما واضح خواهد شد که چرا ما از این واژه ی به خصوص استفاده می کنیم.
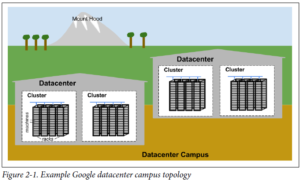
شکل زیر منظره ای از توپولوژی دیتاسنتر گوگل نمایش می دهد:
- ده ها ماشین داخل رک قرار گرفته اند
- رک ها در یک ردیف قرار می گیرند
- یک یا چند ردیف یک cluster را تشکیل می دهد
- معمولا یک ساختمان دیتاسنتر، چندین cluster را در بر می گیرد
- چند ساختمان دیتاسنتر در یک محوطه قرار می گیرند
ماشین ها در داخل دیتاسنترهای داده شده، نیاز دارند تا با یکدیگر ارتباط برقرار کنند، پس ما یک سوییچ ویرچوال سریع ایجاد کردیم با هزاران پورت.
ما این را انجام دادیم با برقرار کردن ارتباط بین صدها سوییچ ساخت گوگل، در یک شبکه ی clos یک پارچه. به اسم jupiter.
دیتاسنترها به یکدیگر متصل هستند با شبکه ی globe-spanning backbone به اسم B4.
B4 یک نرم افزار تعریف شده ی معماری شبکه ای است.
نرم افزار سیستمیی که سخت افزار را سازماندهی می کند
سخت افزار ما باید کنترل و هدایت شود، با استفاده از نرم افزاری که بتواند یک مقیاس بزرگ را کنترل کند. به خطا خوردن های سخت افزاری یکی از مشکلاتی است که ما با نرم افزار مدیریتش می کنیم. با تعداد زیاد سخت افزار در یک cluster، سخت افزارها به طور مداوم و زیاد به خطا می خورند. در یک تک cluster در یک سال عادی، هزاران ماشین با خطا مواجه می شوند و هزاران هارد دیسک خراب می شوند. هنگامی که ما با چندین برابر cluster سروکار داشته باشیم، این اعداد نفس گیر می شوند. از این رو ما می خواهیم که این قبیل مشکلات را از چشم کاربران دور کنیم، و تیم هایی که سرویس ما را اجرا می کنند از به خطا خوردن های سخت افزاری اذیت نشوند. هر دیتاسنتر تیم های جدای خود را دارد، جهت نگهداری سخت افزار و ساختار دیتاسنتر.
مدیریت ماشین ها
Borg، که در تصویر زیر نمایش داده شده، یک cluster توزیع شده از سیستم های عملیاتی می باشد. مشابه Apache Mesos. Borg جاب هاش رو در سطح cluster مدیریت می کند.
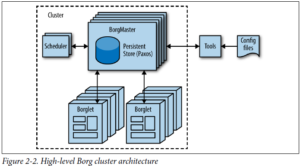
Borg در برابر اجرای جاب های کاربران مسئول است، و همچنین می تواند برای مدت نامحدود، سرورها یا batch processها را اجرا کند. جاب های می توانند تشکیل شده باشند از یک یا چند تسک همسان، هم بخاطر قابل اطمینان سازی و هم بخاطر اینکه یک process به طور معمول نمی تواند کل ترافیک یک cluster را کنترل کند.
زمانیکه Borg یک جاب را شروع می کند، ماشین هایی را برای تسک ها پیدا می کند و به آن ها می گوید که یک برنامه ی سرور را اجرا کنند. Borg به صورت پیوشته این تسک ها را مانیتور می کند. وقتی که یک تسک به درستی عمل نکند، kill می شود تا بر روی یک ماشین دیگر مجدد اجرا شود.
به دلیل اینکه تسک ها خیلی روان به ماشین ها اختصاص داده می شوند، ما نمی توانیم به سادگی تکیه کنیم به IP و پورت ها، برای مراجعه به تسک ها. ما این موضوع را با اضافه کردن یک مرحله ی اضافی حل کردیم.
وقتی که یک جاب اجرا می شود، Borg بک اسم و شماره ی index به هر تسک اختصاص می دهد، با استفاده از Borg Naming Service (BNS). به جای استفاده از IP و پورت، بقیه ی processها به تسک های Borg با استفاده از BNS متصل می شوند. که ترجمه شده ی IP و پورت می باشد. به عنوان مثال مسیر BNS می تواند به صورت یک string مثل <bns>/<cluster/<user>/<job name>/<task number>/ باشد، که به صورت <ipaddress:port> ، resolve می شود.
Borg همچنین مسئول اختصاص منابع به جاب ها می باشد. هر جاب نیاز است که منابع مورد نیاز خود را مشخص کند. با استفاده از یک لیست از نیازمندی ها برای همه ی جاب ها، Borg می تواند بسته بندی کند تسک ها را به صورت بهینه بر روی ماشین ها .
اگر که یک تسک سعی کند تا بیشتر از منابع درخواستیش استفاده کند، Borg آن تسک را kill کرده و ریستارتش می کند.
فضای ذخیره سازی
تسک ها می توانند از local disk ماشین ها به عنوان چک نویس استفاده کنند، ولی ما چندین cluster storage داریم برای ذخیره سازی دائمی.
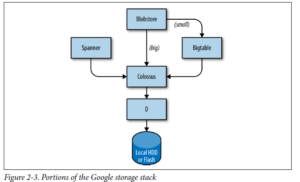
لایه ی ذخیره سازی مسئول این است که به کاربران یک دسترسی ساده و قابل اطمینان به فضای ذخیره سازی موجود برای یک cluster را ارائه دهد. همانطور که در عکس زیر مشخص استريال فضای ذخیره سازی لایه های بسیاری دارد:
- پایینترین لایه، D است. D یک fileserver است که بر روی تمامی ماشین های یک cluster درحال اجرا می باشد. با این حال کاربرانی که می خواهند به دیتای خود دسترسی پیدا کنند، نمی خواهند که حفظ کنن که کدام ماشین دیتای آن ها را ذخیره کرده است، که در این قسمت است که لایه ی بعدی وارد بازی می شود.
- لایه ی بالاسری D که clossus نامیده می شود، یک filesystem در کل cluster می سازد، که مفاهیم یک filesystem معمولی را ارائه می دهد. Clossus جانشین GFS می باشد، Googel File System.
- در بالای clossus، چند سرویس دیتابیس مانند، وجود دارد:
- Bigtable یک سیستم دیتابیسی Nosql می باشد که می تواند دیتابیس های به اندازه ی petabyte رو کنترل کند. Bigtable یک نقشه ی ذخیره شده به صورت پراکنده، توزیع شده ی چند بعدی پایدار است.
- spanner یک رابط مشابه sql ارائه می دهد به کاربرانی که به سازگاری واقعی نیاز دارند در سراسر جهان.
- چند سیستم دیتابیس دیگر هم مانند Blobstore، وجود دارند که هرکدام ویژگی خاص خود را دارد.
Networking
سخت افزار شبکه گوگل از چند طریق کنترل می شود. همانطور که قبلاً بحث شد، از یک شبکه تعریف شده توسط نرم افزار مبتنی بر OpenFlow استفاده می کند و به جای استفاده از سخت افزارهای مسیریابی “هوشمند” ، به اجزای سوئیچینگ “گنگ (dumb)” ارزان تر در ترکیب با یک کنترل کننده مرکزی (کپی شده) که بهترین مسیرهای موجود در شبکه را پیش محاسبه میکند، اتکا می کنند. بنابراین، می توان تصمیمات مسیریابی که پر هزینه است را از روترها دور و از سخت افزار ساده سوئیچینگ استفاده شود.
پهنای باند شبکه باید هوشمندانه تخصیص یابد. همانطور که Borg منابع محاسبه شده ای را که یک کار می تواند استفاده کند محدود می کند، Bandwidth Enforcer) BwE) (مجری پهنای باند) نیز پهنای باند موجود را مدیریت می کند تا میانگین پهنای باند موجود را به حداکثر برساند. بهینه سازی پهنای باند فقط در مورد هزینه نیست: نشان داده شده است که مهندسی متمرکز ترافیک تعدادی از مشکلات را حل می کند که در حالت قدیمی حل آنها از طریق ترکیبی از مسیریابی توزیع شده و مهندسی ترافیک بسیار دشوار است.
بعضی از سرویس ها دارای جاب هایی هستند که روی cluster های مختلف که در سراسر جهان توزیع شده اند، اجرا میشوند. به منظور به حداقل رساندن تأخیر برای خدمات توزیع شده جهانی، ما می خواهیم کاربران را به نزدیکترین مرکز داده با ظرفیت قابل استفاده (available) هدایت کنیم. نرم افزار جهانی متعادل کننده بار (GSLB) توازن بار را در سه سطح انجام می دهد:
- توازن جغرافیایی بار برای درخواست های DNS (به عنوان مثال به www.google.com)، توصیف شده در فصل 19
- تعادل بار در سطح خدمات کاربر (به عنوان مثال ، YouTube یا Google Maps)
- توازن بار در سطح تماس از راه دور (RPC) ، که در فصل 20 شرح داده شده است
دارندگان خدمات یک نام نمادین برای یک سرویس تعیین میکنند که لیستی از آدرس BNS سرورها و ظرفیت موجود یا قابل استفاده در هر یک از مکان ها (به طور معمول با واحد پرس و جو در هر ثانیه (queries per second) اندازه گیری می کنند) مشخص می کنند. سپس GSLB ترافیک را به آدرس های BNS هدایت می کند.
سایر نرم افزارهای سیستم
چندین مولفه دیگر نیز در یک مرکز داده مهم هستند.
سرویس قفل
سرویس قفل Chubby] Bur06] یک API سیستم فایل-مانند را برای نگهداری قفل ها ارائه می دهد. Chubby این قفلها را در مکانهای مرکز داده اداره می کند. از پروتکل Paxos برای توافق ناهمگام (asynchronous Consensus) استفاده می کند (به بخش 23 مراجعه کنید). Chubby همچنین نقش مهمی در انتخاب master دارد. هنگامی که یک سرویس دارای 5 نسخه از یک job است که برای قابلیت اطمینان در حال اجرا هستند اما فقط یک نسخه ممکن است کار واقعی را انجام دهد، Chubby برای انتخاب اینکه کدام نسخه ادامه می یابد استفاده می شود.
داده هایی که باید سازگار باشند به خوبی برای ذخیره سازی در Chubby مناسب هستند. به همین دلیل، BNS از Chubby برای ذخیره mapping بین جفت مسیرهای BNS و IP address:Port استفاده می کند.
مانیتورینگ و سیستم هشدار دهنده (Alerting)
ما می خواهیم اطمینان حاصل کنیم که همه سرویس ها در صورت نیاز اجرا می شوند. بنابراین ، ما بسیاری از موارد برنامه مانیتورینگ Borgmon خود را اجرا می کنیم (به فصل 10 مراجعه کنید). Borgmon به طور منظم معیارهای (metrics) سرورهای مانیتورینگ شده را “پالایش” می دهد. این معیارها می توانند بلافاصله برای هشدار استفاده شوند و همچنین برای استفاده در مرورهای تاریخی (historic overviews) (به عنوان مثال گراف ها) ذخیره می شوند. ما می توانیم مانیتورینگ را به چندین روش استفاده کنیم:
- تنظیم کردن هشدار دهنده برای مشکلات حاد.
- مقایسه رفتار: آیا به روزرسانی نرم افزار سرعت سرور را افزایش داده است؟
- بررسی چگونگی اینکه رفتار مصرفی منابع در طول زمان تکامل می یابد، که برای برنامه ریزی ظرفیت بسیار ضروری است.
زیرساخت نرم افزاری گوگل
معماری نرم افزار ما برای استفاده بهینه از زیرساخت های سخت افزاری ما طراحی شده است. کد ما به شدت چند رشته ای (multithread) است ، بنابراین یک تسک به راحتی می تواند از بسیاری از هسته ها استفاده کند. برای تسهیل داشبورد ، مانیتورینگ و اشکال زدایی، هر سرور دارای یک سرور HTTP است که عیب یابی و آمار را برای یک تسک مشخص ارائه می دهد.
همه سرویس های Google با استفاده از زیرساخت Remote Procedure Call) RPC) به نام Stubby با یکدیگر ارتباط برقرار می کنند. نسخه منبع باز، gRPC، در دسترس است. اغلب اوقات، حتی در صورت نیاز به فراخوانی برنامه فرعی در برنامه محلی، فراخوانی RPC برقرار می شود. در صورت نیاز به افزایش ماژولاریتی و یا رشد کد سرور، امکان بازسازی فراخوانی به یک سرور دیگر آسان تر می شود. GSLB می تواند تعادل بار RPC ها را به همان روشی که سرویس های قابل رویت خارجی را بارگیری می کند، بارگیری کند.
یک سرور درخواستهای RPC را از قسمت فرانت اند خود دریافت می کند و RPC ها را به بک اند خود ارسال می کند. در اصطلاح سنتی ، فرانت اند سرویس گیرنده و بک اند، سرور نامیده می شود.
داده ها با استفاده از بافرهای پروتکل به و از RPC منتقل می شوند که غالباً به اختصار “protobufs” می شوند، که مشابه Apache’s Thrift است. بافرهای پروتکل نسبت به XML برای سریال سازی داده های ساختاری مزایای زیادی دارند: استفاده از آنها ساده تر ، 3 تا 10 برابر کوچکتر ، 20 تا 100 برابر سریعتر و دارای ابهام و پیچیدگی کمتری است.
محیط توسعه ما
سرعت توسعه برای گوگل بسیار مهم است ، بنابراین برای استفاده از زیرساخت های خود یک محیط توسعه کامل ایجاد کرده ایم.
جدا از چند گروه که مخازن منبع باز اختصاصی خود را دارند (مثلاً اندروید و کروم، مهندسان نرم افزار گوگل از یک مخزن مشترک استفاده می کنند. این چند پیامد عملی مهم برای گردش کار ما دارد:
- اگر مهندسان در خارج از پروژه خود با مشكلی روبرو شوند ، می توانند این مشكل را برطرف كنند ، تغییرات پیشنهادی ( “لیست تغییر” یا CL) را برای بررسی به مالك ارسال كنند و CL را به قسمت داکیومنتیشن ارسال كنند.
- تغییرات کد منبع در هر پروژه نیاز به بازبینی دارد. کلیه نرم افزارها قبل از ارسال بررسی می شوند.
وقتیکه نرم افزار ساخته شد، درخواست ساخت برای سرورهای ساخت در یک مرکز داده ارسال می شود. حتی ساختهای بزرگ نیز به سرعت اجرا می شوند ، زیرا بسیاری از سرورهای ساخت می توانند به صورت موازی کامپایل شوند. این زیرساخت برای آزمایش مداوم نیز مورد استفاده قرار می گیرد. با هر بار ارسال CL ، آزمایشات روی کلیه نرم افزارهایی که ممکن است به طور مستقیم یا غیرمستقیم به آن CL وابسته باشند ، اجرا می شود. اگر چارچوب مشخص کند که این تغییر احتمالاً باعث شکست سایر قسمتهای سیستم شده است ، این تغییر را به مالک اطلاع می دهد. برخی از پروژه ها از سیستم فشار سبز (push-on-green) استفاده می کنند که در آن نسخه جدید پس از گذراندن آزمایشات به طور خودکار به سمت تولید سوق داده می شود.
شکسپیر: یک سرویس نمونه
برای ارائه مدلی از نحوه استقرار فرضی یک سرویس در محیط تولید گوگل، بیایید یک سرویس نمونه را بررسی کنیم که با چندین فناوری گوگل ارتباط برقرار می کند. فرض کنید ما می خواهیم سرویسی را ارائه دهیم که به شما اجازه دهد در تمام کارهای شکسپیر تعیین کنید که یک کلمه در چه مکانی استفاده می شود.
ما می توانیم این سیستم را به دو قسمت تقسیم کنیم:
- یک دسته کامپوننت که تمام متن های شکسپیر را می خواند ، یک فهرست ایجاد می کند و فهرست را در یک جدول بزرگ می نویسد. این جاب (کار) فقط یکبار یا شاید خیلی کم نیاز به اجرا دارد (همانطور که هرگز نمی دانید ممکن است متن جدیدی کشف شود!).
- نمای برنامه ای که به درخواست های کاربر نهایی رسیدگی می کند. این جاب همیشه بالا است ، زیرا کاربران در تمام مناطق زمانی می خواهند در کتابهای شکسپیر جستجو کنند.
کامپوننت دسته ای یک MapReduce است که شامل سه مرحله است.
مرحله نقشه برداری متون شکسپیر را می خواند و آنها را به کلمات جداگانه تقسیم می کند.
این در صورتی سریعتر انجام می شود که به طور موازی توسط چند کارگر (workers) انجام شود.
مرحله شافل، تاپل ها را با کلمه مرتب می کند.
در مرحله کاهش ، یک گروه (از کلمه ، لیست مکان ها) ایجاد می شود.
هر تاپل در یک Bigtable با استفاده از کلمه به عنوان کلید در یک ردیف نوشته می شود.
چرخه یک درخواست
شکل 2-4 نحوه سرویس دهی به درخواست کاربر را نشان می دهد: ابتدا کاربر در مرورگر خود آدرس shakespeare.google.com را می نویسد. برای به دست آوردن آدرس IP مربوطه ، دستگاه کاربر آدرس را با سرور DNS خود حل می کند. این درخواست در نهایت به سرور DNS Google منتهی می شود ، که با GSLB صحبت می کند. همانطور که GSLB بار ترافیک بین سرورهای فرانت اند را در مناطق مختلف پیگیری می کند ، تعیین میکند کدام آدرس IP سرور برای ارسال به کاربر انتخاب شود.
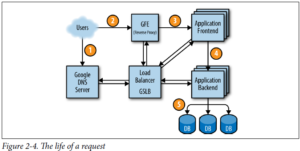
مرورگر در این IP به سرور HTTP متصل می شود. این سرور (به نام Google Frontend یا GFE) یک پروکسی معکوس است که اتصال TCP را قطع می کند. GFE جستجو می کند که کدام سرویس مورد نیاز است (جستجوی وب ، نقشه ها ، یا در این مورد – شکسپیر). مجدداً با استفاده از GSLB ، سرور یک سرور فرانت اند شکسپیر را پیدا می کند و برای آن سرور RPC حاوی درخواست HTML ارسال می کند.
سرور شکسپیر درخواست HTML را تجزیه و تحلیل می کند و یک protobuf شامل کلمه برای جستجو می سازد. سرور فرانت اند شکسپیر اکنون باید با سرور بک اند شکسپیر تماس بگیرد: سرور فرانت اند با GSLB تماس می گیرد تا آدرس BNS یک سرور بک اند مناسب و بارگیری نشده را بدست آورد. این سرور بک اند شکسپیر اکنون با یک سرور Bigtable تماس می گیرد تا داده های درخواستی را بدست آورد.
جواب به پاسخ protobuf نوشته شده و به سرور بک اند شکسپیر بازگردانده می شود. بک اند protobuf حاوی نتایج را به سرور فرانت اند شکسپیر تحویل می دهد ، که HTML را اسمبل (جمع بندی) می کند و پاسخ را به کاربر برمی گرداند.
کل این زنجیره از وقایع در یک چشم به هم زدن اجرا می شود – فقط چند صد میلی ثانیه! از آنجا که بسیاری از قطعات متحرک درگیر هستند ، در بسیاری از نقاط پتانسیل خرابی وجود دارد. به طور خاص ، یک GSLB ناموفق باعث ویرانی خواهد شد. با این حال ، خط مشی های Google برای آزمایش دقیق و عرضه دقیق ، علاوه بر روش های پیشگیرانه بازیابی خطا مانند تخریب نامطبوع ، به ما امکان می دهد تا سرویس قابل اعتماد مورد انتظار کاربران خود را ارائه دهیم. از این گذشته ، افراد به طور منظم از www.google.com استفاده می کنند تا بررسی کنند آیا اتصال اینترنت آنها به درستی تنظیم شده است.
جاب و داده
آزمایش بار مشخص کرد که سرور بک اند ما می تواند در حدود 100 پرسش در ثانیه (QPS) را کنترل کند. آزمایشات انجام شده با تعداد محدودی از کاربران باعث می شود که حداکثر بار در حدود 3،470 QPS را انتظار داشته باشیم ، بنابراین حداقل به 35 تسک نیاز داریم. با این حال ، ملاحظات زیر به این معنی است که ما حداقل به 37 تسک در کار یا 2N + نیاز داریم:
- در هنگام به روزرسانی ، هر بار یک وظیفه غیرقابل دسترس خواهد بود و 36 وظیفه بر جای خواهد ماند
- ممکن است در هنگام به روزرسانی کار ، خرابی دستگاه رخ دهد و فقط 35 تسک باقی بماند ، که برای انجام حداکثر بار کافی است.
بررسی دقیق ترافیک کاربران نشان می دهد حداکثر میزان استفاده ما در سطح جهان توزیع شده است: 1430 QPS از آمریکای شمالی ، 290 از آمریکای جنوبی ، 1400 از اروپا و آفریقا و 350 از آسیا و استرالیا. ما به جای اینکه همه بک اند ها را در یک سایت قرار دهیم ، آنها را در ایالات متحده آمریکا ، آمریکای جنوبی ، اروپا و آسیا توزیع می کنیم. اجازه دادن به اضافه کاری N + 2 برای هر منطقه به این معنی است که در پایان با 17 کار در ایالات متحده آمریکا ، 16 کار در اروپا و 6 کار در آسیا انجام خواهیم شد. با این حال ، ما تصمیم می گیریم برای کاهش سربار N + 2 به N + 1 از 4 تسک (به جای 5) در آمریکای جنوبی استفاده کنیم. در این حالت ، ما مایل به تحمل خطر اندکی تأخیر بالاتر در ازای کاهش هزینه سخت افزار هستیم: اگر GSLB وقتی مرکز داده ما در آمریکای جنوبی بیش از ظرفیت است ،ترافیک را از قاره ای به قاره دیگر هدایت کند ، می توانیم 20٪ از منابع خود را صرف سخت افزار کنیم. در مناطق بزرگتر ، ما وظایف را برای انعطاف پذیری بیشتر در دو یا سه cluster گسترش می دهیم.
از آنجا که بک اند ها باید با Bigtable که داده ها را در اختیار دارد ارتباط بگیرند ، بنابراین ما باید این عنصر ذخیره سازی را نیز به صورت استراتژیک طراحی کنیم. یک بک اند در آسیا که با یکBigtable در ایالات متحده ارتباط می گیرد مقدار قابل توجهی تأخیر را اضافه می کند ، بنابراین ما Bigtable را در هر منطقه تکرار می کنیم. تکثیر Bigtable از دو طریق به ما کمک می کند: در صورت خرابی سرور Bigtable قابلیت انعطاف پذیری را فراهم می کند و تأخیر دسترسی به داده را کاهش می دهد. در حالی که Bigtable فقط سازگاری نهایی را ارائه می دهد ، اما این یک مشکل اساسی نیست زیرا ما نیازی به بروزرسانی متوالی مطالب نداریم.
ما اصطلاحات زیادی را در اینجا معرفی کرده ایم. گرچه نیازی به یادآوری همه آنها نیست ، اما برای فریم ورک بسیاری از سیستمهای دیگری که بعداً به آنها اشاره خواهیم کرد ، مفید است.

“I’m a self-motivated and curious person with a weapon named “search
0 دیدگاه در “SRE-بخش سوم” افزودن → خودتان