

کافکا چیست؟
Apache Kafka به عنوان یک سیستم پیام رسانی publish-subscribe برای مدیریت حجم عظیمی از داده ها در LinkedIn توسعه داده شده است و یک Queue قوی است که می تواند حجم بالایی از داده ها را مدیریت کند و شما را قادر می سازد تا پیام ها را از یک نقطه به نقطه دیگر منتقل کنید. کافکا برای دریافت پیام های آفلاین و آنلاین مناسب است. پیامهای کافکا روی دیسک باقی می مانند و در داخل cluster تکرار می شوند تا از از دست رفتن اطلاعات جلوگیری شود. کافکا در بالای سرویس همگام سازی ZooKeeper ساخته شده است. برای تجزیه و تحلیل داده های streaming در real-time ، بسیار خوب با Apache Storm و Spark ادغام می شود.
سیستم پیام رسانی چیست؟
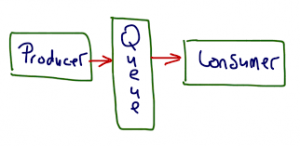
یک سیستم پیام رسانی مسئول انتقال داده ها از یک برنامه به برنامه دیگر است ، بنابراین برنامه ها می توانند روی داده ها تمرکز کنند ، اما نگران نحوه به اشتراک گذاری آنها نباشند. پیام رسانی Distributed بر اساس مفهوم reliable message queuing است، که در آن پیامها بین برنامه های سرویس گیرنده و سیستم پیام رسانی به صورت async به اشتراک گذاشته می شوند. دو نوع الگوی پیام رسانی در دسترس است-یکی point to point و دیگری سیستم publish-subscribe.
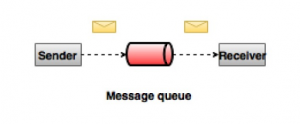
Point to Point Messaging System
در یک سیستم point-to-point ، پیامها در یک صف باقی می مانند. یک یا چند consumer می توانند پیام ها را از صف دریافت کنند ، اما حداکثر یک کاربر می تواند یک پیام خاص را دریافت کند. هنگامی که consumer پیامی را از صف می خواند ، پیام از آن صف حذف می شود. نمونه معمولی این سیستم یک سیستم پردازش سفارش است ، که در آن هر سفارش توسط یک پردازنده سفارش پردازش می شود ، اما پردازنده های چند منظوره می توانند همزمان کار کنند. نمودار زیر ساختار را نشان می دهد.
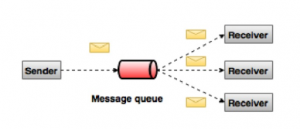
Publish-Subscribe Messaging System
در سیستم publish-subscribe ، پیام ها در یک topic پابرجا هستند. بر خلاف سیستم point-to-point ، consumer ها می توانند در یک یا چند topic مشترک شوند و همه پیام های آن topic را استفاده کنند. در سیستم publish-subscribeء ، producer های پیام را publisher و consumer های پیام را subscriber می نامند. یک مثال واقعی Dish TV است که کانال های مختلفی مانند ورزش ، فیلم ، موسیقی و غیره را publish می کند و هر کسی می تواند در کانال ها subscribe کند و هر زمان که کانال های subscribe شده ی آنها در دسترس باشد آنها را دریافت کند.
فواید کافکا
- Reliability – کافکا distributed ، پارتیشن بندی شده و replicated می باشد.
- Scalability – سیستم پیام کافکا به راحتی و بدون downtime می تواند scale بخورد.
- Durability – کافکا از Distributed commit log استفاده می کند که به این معنی است که پیامها تا آنجا که ممکن است روی دیسک باقی می مانند ، بنابراین دوام دارد.
- Performance – کافکا هم برای publishing و هم برای subscribing پیام از ظرفیت بالایی برخوردار است. کافکا عملکرد خود را حتی با وجود ذخیره سازی ترابایت ها پیام، حفظ می کند.

Event چیست؟
event هر نوع رویداد ، حادثه یا تغییری است که توسط نرم افزار یا برنامه های کاربردی شناسایی یا ثبت می شود. به عنوان مثال ، پرداخت ، کلیک روی وب سایت یا هر عمل دیگری در برنامه ، همراه با شرح آنچه اتفاق افتاده است.
به عبارت دیگر ، یک event ترکیبی از notification است که می تواند برای ایجاد فعالیت ها و state های دیگر استفاده شود. این state معمولاً نسبتاً کوچک است ، مثلاً کمتر از یک مگابایت یا بیشتر ، و معمولاً در برخی از قالب های ساختار یافته نشان داده می شود ، مثلاً در JSON یا شیئی که با Apache Avro یا Protocol Buffer ها serialized شده است.
Kafka and Events – Key/Value Pairs
کافکا بر اساس انتزاع یک distributed commit log است. با تقسیم یک log به پارتیشن ها ، کافکا قادر است سیستم ها را مقیاس بندی کند. به این ترتیب ، کافکا event ها را به عنوان key/value pairs مدل می کند. Key ها و value ها فقط دنباله ای از بایت ها هستند ، اما در زبان برنامه نویسی دلخواه شما ، اغلب اشیاء ساختار یافته ای هستند که در سیستم زبان شما نشان داده می شوند. کافکا ترجمه بین انواع زبان و بایت های داخلی را، serialization و deserialization می نامد. قالب serialized معمولاً JSON ، JSON Schema ، Avro یا Protobuf است.
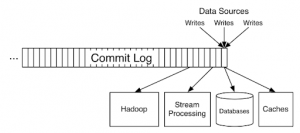
Value ها معمولاً نمایش serialized یک شیء در دامنه ی برنامه یا نوعی ورودی پیام خام هستند.
Key ها هم همچنین می توانند اشیاء دامنه پیچیده ای باشند اما اغلب انواع اولیه مانند رشته ها یا اعداد صحیح هستند. بخش key یک event کافکا لزوماً یک شناسه منحصر به فرد برای event نیست ، مانند primary key یک ردیف در پایگاه داده رابطه ای. بیشتر شبیه به شناسه یک entity در سیستم ، مانند یک کاربر یا سفارش خاص است.
چرا کافکا؟ (مزایا و موارد استفاده)
کافکا توسط بیش از 100،000 سازمان در سراسر جهان مورد استفاده قرار می گیرد و توسط جامعه ای در حال توسعه از توسعه دهندگان حرفه ای پشتیبانی می شود که دائماً در زمینه stream processing پیشرفت می کنند. به دلیل توان بالای کافکا ، تحمل خطا ، انعطاف پذیری و مقیاس پذیری ، تقریباً موارد استفاده از آن در همه صنایع وجود دارد – از بانکداری گرفته تا حمل و نقل و اینترنت اشیا. ما معمولاً از کافکا بیشتر برای اهداف زیر استفاده می کنیم:
Data Integration
کافکا می تواند تقریباً به هر منبع داده دیگری در سیستم های اطلاعاتی سنتی شرکت ، پایگاه های داده مدرن یا در cloud متصل شود. این یک نقطه ادغام کارآمد با اتصال دهنده های داده داخلی است ، بدون پنهان کردن منطق یا مسیریابی در زیرساخت های شکننده و متمرکز.
Metrics & monitoring
کافکا اغلب برای نظارت بر داده های عملیاتی استفاده می شود. این شامل جمع آوری آمار از برنامه های distributed برای تولید فیدهای متمرکز با معیارهای real-time است.
Log aggregation
یک سیستم مدرن معمولاً یک سیستم distributed است و داده های logging باید از اجزای مختلف سیستم در یک مکان متمرکز شوند. کافکا غالباً با متمرکز کردن داده ها از همه منابع ، صرف نظر از شکل یا حجم ، به عنوان یک منبع واحد عمل می کند.
Stream processing
انجام محاسبات real-time در event stream ها یکی از شایستگی های اصلی کافکا است. از پردازش real-time داده ها تا dataflow programming ، کافکا processes stream ها را ذخیره و پردازش می کند ، به همان شکل که تولید می شوند ، در هر مقیاسی.
Publish-subscribe messaging
کافکا به عنوان یک سیستم پیام رسانی pub/sub توزیع شده ، به خوبی به عنوان نسخه مدرنی از message broker عمل می کند. هر زمان که فرایندی که event ها را ایجاد می کند باید از فرایند یا از فرایندهای دریافت event ها جدا شود ، کافکا راهی مقیاس پذیر و انعطاف پذیر برای انجام کار این است.
معماری کافکا – مفاهیم بنیادی
Kafka Topics
اساسی ترین واحد کافکا، topic است که چیزی شبیه یک جدول در پایگاه داده رابطه ای است. به عنوان توسعه دهنده ای که از کافکا استفاده می کنید ، topic یک موضوع انتزاعی است که احتمالاً باید بیشتر به آن فکر کنید. شما topic های متفاوتی را برای نگهداری انواع مختلف event ها و topic های مختلف را برای نگهداری نسخه های فیلتر شده و تغییر یافته از یک نوع event ایجاد می کنید.
topic یک log از event ها است. درک log ها بسیار ساده است ، زیرا آنها ساختارهای داده ساده با مفاهیم معروف هستند. اول اینکه آنها فقط ضمیمه می شوند: هنگامی که یک پیام جدید را در یک log می نویسید ، این پیام همیشه به آخر می رود. دوم اینکه آنها را فقط می توان با جستجوی یک arbitrary offset در log، و سپس با اسکن ورودی های متوالی log ، خواند. ثالثاً اینکه event های موجود در log تغییر ناپذیر هستند. مفاهیم ساده یک log برای کافکا این را امکان پذیر می سازد که سطح بالایی از توان پایدار را در داخل و خارج از topic ها ارائه دهد و همچنین استدلال در مورد تکرار topic ها را آسان تر می کند.
Log ها اساساً چیزهای با دوامی هستند. سیستم های پیام رسانی سنتی سازمانی دارای topic ها و صف هایی هستند که پیام ها را موقتا ذخیره می کند تا بین مبدا و مقصد buffer شود.
از آنجا که topic های کافکا، log هستند ، هیچ چیز به طور ذاتا موقت در مورد داده های موجود در آنها وجود ندارد. هر topic را می توان تنظیم کرد که داده ها پس از رسیدن به سن معین (یا اینکه topic به طور کلی به اندازه مشخصی برسد) منقضی شود ، از ثانیه ها تا سالها یا حتی برای حفظ نامحدود پیامها. Log های مربوط به topic کافکا، فایل هایی هستند که روی دیسک ذخیره می شوند. وقتی event ی را بر روی topic می نویسید ، ماندگار خواهد بود.
سادگی log و تغییر ناپذیری مطالب موجود در آن، کلید موفقیت کافکا به عنوان یک جزء مهم در زیرساخت های داده مدرن است.
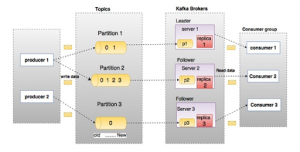
Kafka Partitioning
اگر topic محدود به زندگی کامل بر روی یک ماشین باشد ، این امر محدودیتی اساسی در توانایی مقیاس پذیری کافکا ایجاد می کند. پارتیشن بندی می تواند topic های زیادی را در بسیاری از ماشین ها مدیریت کند – به هر حال کافکا یک سیستم distributed است – اما هیچ topic ی هرگز نمی تواند خیلی بزرگ شود که تعداد زیادی خواندن و نوشتن را بر روی خود بپذیرد. خوشبختانه کافکا ما را بدون گزینه در اینجا نمی گذارد: به ما این امکان را می دهد که topic را تقسیم بندی کنیم.
پارتیشن بندی، یک topic log را می گیرد و آن را به چندین log تقسیم می کند ، که هر کدام می توانند در یک node جداگانه در cluster کافکا زندگی کنند. به این ترتیب ، کار ذخیره پیام ها ، نوشتن پیام های جدید و پردازش پیام های موجود را می توان بین بسیاری از node های cluster تقسیم کرد.
How Partitioning Works
پس از اینکه یک topic را بین پارتیشن ها تقسیم کردیم ، ما به راهی نیاز داریم که تصمیم بگیریم کدام پیام ها را در کدام پارتیشن بنویسیم. به طور معمول ، اگر یک پیام فاقد key باشد ، پیام های بعدی به صورت round-robin بین همه پارتیشن های topic توزیع می شود. در این حالت ، همه پارتیشن ها سهم مساوی از داده ها را دریافت می کنند ، اما ما هیچ نوع نظمی در پیام های ورودی را حفظ نمی کنیم. اگر پیام دارای key باشد ، پارتیشن مقصد از یک hash ایجاد شده از key، محاسبه می شود. این به کافکا این اطمینان را می دهد که پیام هایی که key یکسانی دارند همیشه در یک پارتیشن یکسان قرار می گیرند و بنابراین همیشه مرتب هستند.
به عنوان مثال ، اگر event هایی را تولید می کنید که همگی به یک client مرتبط هستند ، استفاده از شناسه client به عنوان key تضمین می کند که همه event های یک client معین همیشه به ترتیب به دست شما می رسد. این قضیه این امکان را ایجاد می کند که یک key بسیار فعال یک پارتیشن بزرگتر و فعالتر ایجاد کند ، اما این خطر در عمل کوچک است و هنگامی که خود را نشان دهد قابل کنترل است. اغلب برای حفظ ترتیب key ها ارزش آن را دارد.
Kafka Brokers
تا کنون ما در مورد topic ها ، event ها و پارتیشن ها صحبت کرده ایم ، اما در مورد رایانه های واقعی موجود در تصویر خیلی صریح نبوده ایم. از نظر زیرساخت های فیزیکی ، کافکا از شبکه ای از ماشین آلات به نام بروکر تشکیل شده است. در استقرار امروزی، ممکن است اینها سرورهای فیزیکی مجزا نباشند ، بلکه container هایی باشند که بر روی pod هایی اجرا می شوند که روی سرورهای مجازی کار می کنند و روی پردازنده های واقعی در مرکز داده فیزیکی در جایی کار می کنند. با این حال ، آنها مستقر هستند ، آنها ماشینهای مستقلی هستند که هر کدام فرایند بروکر کافکا را اجرا می کنند. هر بروکر مجموعه ای از پارتیشن ها را میزبانی می کند و درخواست های ورودی را برای نوشتن event جدید در آن پارتیشن ها یا خواندن event ها از آنها انجام می دهد. بروکر ها همچنین replicate پارتیشن ها بین یکدیگر را مدیریت می کنند.
Replication
نباید هر پارتیشن را فقط در یک بروکر ذخیره کنیم ، چه بروکر ها bare-metal server یا چه managed containers باشند ، زیرا هم خودشان و هم فضای ذخیره سازی اصلی آنها مستعد خرابی هستند ، بنابراین برای ایمن نگه داشتن آنها باید داده های پارتیشن را در چندین بروکر دیگر کپی کنیم. آن نسخه های کپی، follower نامیده می شوند ، در حالی که پارتیشن اصلی leader است. وقتی داده هایی را برای leader ایجاد می کنید – به طور کلی ، خواندن و نوشتن روی leader انجام می شود – leader و follower ها با هم کار می کنند تا نوشته های جدید را بر روی follower ها کپی کنند.
این به طور خودکار اتفاق می افتد ، و در حالی که می توانید برخی از تنظیمات را در producer تنظیم کنید تا سطوح متفاوتی از ضمانت دوام را ایجاد کنید ، این معمولاً فرآیندی نیست که شما باید به عنوان یک توسعه دهنده در ایجاد سیستم های روی کافکا به آن فکر کنید. تنها چیزی که شما به عنوان یک توسعه دهنده باید بدانید این است که داده های شما ایمن هستند و اگر یک node در cluster بیفتد ، دیگری نقش آن را بر عهده می گیرد.

ZooKeeper
یکی از اجزای مهم کافکا، Apache Zookeeper است که یک سرویس configuration و همگام سازی distributed است. Zookeeper به عنوان رابط هماهنگی بین بروکرهای کافکا و consumer ها عمل می کند. سرورهای کافکا اطلاعات را از طریق Zookeeper cluster به اشتراک می گذارند. کافکا داده های اساسی مانند اطلاعات مربوط به topic ها، بروکرها ، consumer ها و غیره را در Zookeeper ذخیره می کند.
از آنجا که تمام اطلاعات مهم در Zookeeper ذخیره می شود و به طور معمول این داده ها را در مجموعه خود تکرار می کند ، fail شدن بروکر کافکا، بر وضعیت cluster کافکا تأثیر نمی گذارد. کافکا پس از راه اندازی مجدد بروکر وضعیت را بازیابی می کند. این کار زمان کافی را برای کافکا به ارمغان می آورد. انتخاب leader بین بروکر های کافکا نیز با استفاده از Zookeeper در صورت شکست leader انجام می شود.
حالا بیایید از cluster کافکا خارج شویم و به برنامه هایی که از کافکا استفاده می کنند: producer ها و consumer ها ، برسیم. اینها برنامه های سرویس گیرنده، حاوی کد شما هستند ، پیامها را در topic ها قرار می دهند و پیامهای topic ها را می خوانند. هر جزء از بستر کافکا که بروکر کافکا نیست ، یا producer است یا consumer. تولید و مصرف، نحوه ارتباط شما با یک cluster است.
Kafka Producers
Producer ها ناشر پیام های یک یا چند topic کافکا هستند. Producer ها داده ها را برای بروکر های کافکا ارسال می کنند. هر بار که یک Producer پیامی را برای یک بروکر منتشر می کند ، بروکر به سادگی پیام را به آخرین بخش فایل اضافه می کند. در واقع ، پیام به یک پارتیشن پیوست می شود.
سطح API کتابخانه producer نسبتاً سبک است: در جاوا ، کلاسی به نام KafkaProducer وجود دارد که از آن برای اتصال به cluster استفاده می کنند. شما به این کلاس نقشه ای از پارامترهای تنظیمات ، از جمله آدرس برخی از بروکر ها در cluster ، هرگونه تنظیمات امنیتی مناسب و سایر تنظیماتی که رفتار شبکه producer را تعیین می کند ، می دهید. کلاس دیگری به نام ProducerRecord وجود دارد که از آن برای نگه داشتن key-value pair که می خواهید به cluster ارسال کنید استفاده می کنید. این تمام سطح API برای تولید پیام است.
Kafka Consumers
اطلاعات بروکر ها را می خوانند. Consumer ها در یک یا چند topic مشترک می شوند و پیام های منتشر شده را با کشیدن داده ها از بروکر ها مصرف می کنند.
KafkaConsumer اتصال و پروتکل شبکه را درست مانند KafkaProducer مدیریت می کند ، اما یک داستان بسیار بزرگتر وجود دارد. کافکا با صف های پیام قدیمی متفاوت است زیرا خواندن یک پیام آن را از بین نمی برد. هنوز در دسترس است تا توسط هر Consumer دیگری که ممکن است به آن علاقه مند باشد ، خوانده شود. در واقع ، در کافکا کاملاً طبیعی است که بسیاری از Consumer ها از یک topic بخوانند.
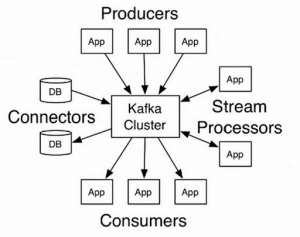
اکوسیستم کافکا
اگر تمام چیزی که شما داشتید بروکرهایی با پارتیشن های مدیریت شده، replicated topic ها با یک مجموعه producer ها و consumer های ثابت با event های خواندن و نوشتن بود، شما در واقع یک سیستم بسیار مفید خواهید داشت. اما اگر با پترن های پیچیده تری مواجه بشید، امکان دارد که این نیاز را احساس کنید که با استفاده از core کافکا، برنامه هایی ایجاد کنید برای راحت تر کردن مسیر.
نوشتن این کد توسط خود شما وسوسه انگیز است ، اما کافکا این کار را برای شما راحت کرده است. Kafka Connect و Kafka Streams نمونه هایی از این نوع کد ها هستند که به کمک شما می آیند.
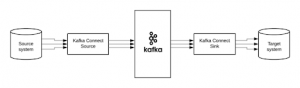
Kafka Connect
در دنیای ذخیره و بازیابی اطلاعات ، سیستم های متفاوتی وجود دارند. گاهی دوست دارید داده های آن سیستم های دیگر وارد topicهای کافکا شود و گاهی دوست دارید داده های مربوط به topicهای کافکا وارد آن سیستم ها شود. به عنوان API یکپارچه سازی Apache Kafka ، این دقیقاً همان کاری است که Kafka Connect انجام می دهد.
Kafka Connect چه کار می کند؟
از یک سو ، Kafka Connect یک اکوسیستم اتصال دهنده های قابل اتصال است و از سوی دیگر ، یک برنامه client است. به عنوان یک برنامه clientی ، Connect یک server process است که بر روی سخت افزار مستقل از بروکرهای کافکا اجرا می شود. Kafka Connect مقیاس پذیر و مقاوم در برابر خطا است ، بدین معنی که شما می توانید نه تنها یک Connect worker ، بلکه مجموعه ای از Connect worker ها را که بار انتقال داده ها را در داخل و خارج از کافکا از و به سیستم های خارجی تقسیم می کنند ، اجرا کنید. Kafka Connect همچنین کد را از کاربر دور می کند و در عوض فقط پیکربندی JSON برای اجرا نیاز دارد.
نحوه کار Kafka Connect
یک Connect worker یک یا چند اتصال را اجرا می کند. کانکتور یک جزء قابل اتصال است که وظیفه برقراری ارتباط با سیستم خارجی را بر عهده دارد. منبع اتصال داده ها را از یک سیستم خارجی می خواند و آنها را در یک topic کافکا ایجاد می کند. یک اتصال sink با یک یا چند topic کافکا به اشتراک می گذارد و پیامهایی را که می خواند در یک سیستم خارجی می نویسد. هر کانکتور یا یک منبع یا یک sink است ، اما شایان ذکر است که cluster کافکا فقط در هر دو مورد به producer یا consumer مراجعه می کند. هر چیزی که بروکر نباشد producer یا consumer است.
Kafka Streams
Kafka Streams یک کتابخانه سمت client برای ایجاد برنامه های کاربردی و microservice ها است ، جایی که داده های ورودی و خروجی در یک Apache Kafka cluster ذخیره می شود. این سادگی نوشتن و استقرار برنامه های کاربردی استاندارد جاوا و اسکالا در سمت کلاینت را با مزایای فناوری cluster سمت سرور کافکا ترکیب می کند.
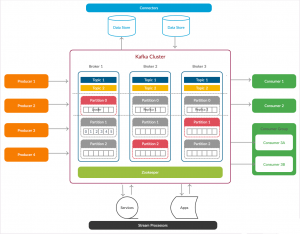
نمای کلی cluster کافکا

“I’m a self-motivated and curious person with a weapon named “search
0 دیدگاه در “Apache Kafka” افزودن → خودتان